
오버피팅은 실험하고 있는 특정 데이터를 필요 이상으로 학습한 상태로, 일반화 성능이 낮아지는 문제를 초래합니다.
- 데이터의 수 증가(ex. augmentation을 통해 늘림)
- 데이터에 노이즈 추가 : outlier에 robust하도록 합니다. (1,2번이 거의 같은 맥락이다. 데이터 어그멘테이션을 통해 데이터의 수가 증가하지만 증가한 데이터들은 원본의 변형이고 이 변형을 노이즈라고 치환해도 무방하므로.)
- feature를 줄이거나, layer를 줄여 모델의 복잡도를 낮춥니다.
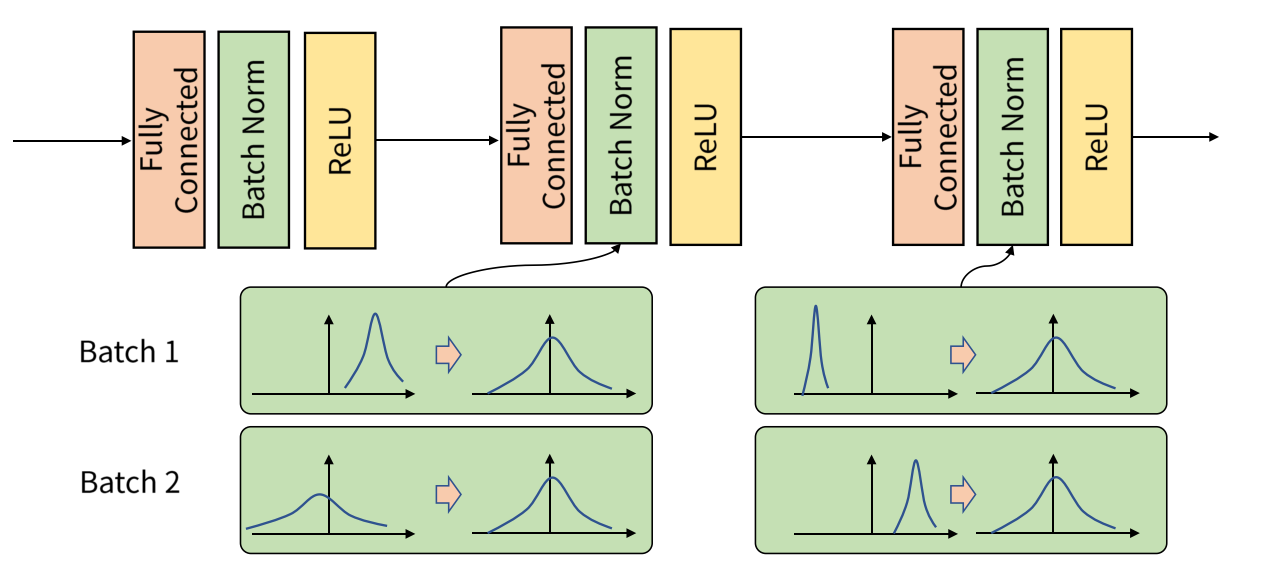
- 배치 정규화(batch normalization) : mini batch 별로 분산과 표준편차를 구해 분포를 조정합니다. 이를 통해 가중치의 초깃값에 의존하지 않고 강제로 활성화 값을 적절히 분포되도록 합니다.
- 혹은 dropout을 통해 각 레이어의 뉴런 간 연결을 랜덤하게 끊음으로써 과적합을 막기도 합니다.
- 가중치 감소(weight decay) : 손실 함수에 L1 loss, 혹은 L2 loss 값을 더하여, 가중치에 비례하는 패널티를 부과하여 오버피팅을 억제합니다.
- L1 규제 : 불필요한 가중치는 0으로 만들어버림 → robust하진 않음
- L2 규제 : 불필요한 가중치는 0에 가깝게 만들어버림

위의 수식 그림을 살펴보면, 손실 함수에 규제를 걸어주는 loss값을 더해주는데 loss값 앞에 람다를 곱합니다.
람다의 역할은 규제의 강약을 조절하는 역할을 합니다. 람다가 작으면 규제가 약하게, 크면 규제 또한 강하게 적용됩니다.
참고
L1, L2 Norm, Loss, 정규화
https://junklee.tistory.com/29
L1, L2 Norm, Loss, Regularization?
정규화 관련 용어로 자주 등장하는 L1, L2 정규화(Regularization)입니다. 이번에는 단순하게 이게 더 좋다 나쁘다보다도, L1, L2 그 자체가 어떤 의미인지 짚어보고자합니다. 사용된 그림은 위키피디아
junklee.tistory.com
릿지회귀 vs 라쏘회귀 vs 엘라스틱넷
https://ratsgo.github.io/machine%20learning/2017/05/22/RLR/
Regularized Linear Regression · ratsgo's blog
이번 글에서는 회귀계수들에 제약을 가해 일반화(generalization) 성능을 높이는 기법인 Regularized Linear Regression에 대해 살펴보도록 하겠습니다. 이번 글 역시 고려대 김성범 교수님, 같은 대학의 강
ratsgo.github.io
배치 정규화
https://gaussian37.github.io/dl-concept-batchnorm/#batch-normalization-1
배치 정규화(Batch Normalization)
gaussian37's blog
gaussian37.github.io
'AI > AI 지식' 카테고리의 다른 글
| [Python] *args, **kwargs 는 무엇이며, 왜 사용하는가? (0) | 2022.09.02 |
|---|---|
| [Statistics/Math] “likelihood”와 “probability”의 차이는 무엇일까요? (0) | 2022.08.23 |
| [Python] 파이썬에서 namespace란 무엇인가요? (0) | 2022.08.23 |
| [Machine Learning] Markov Chain을 고등학생에게 설명하려면 어떤 방식이 제일 좋을까요? (0) | 2022.08.23 |
| [Machine Learning] 앙상블 보팅/배깅/부스팅/스태킹 정리 (0) | 2022.08.15 |