
1. 앙상블 학습이란?
앙상블 학습(Ensemble Learning)은 여러 개의 분류기를 생성하고, 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법을 말합니다.
강력한 하나의 모델을 사용하는대신 보다 약한 모델 여러개를 조합하여 더 정확한 예측에 도움을 주는 방식입니다.
현실세계로 예를 들면, 어려운 문제를 해결하는데 한 명의 전문가보다 여러명의 집단지성을 이용하여 문제를 해결하는 방식을 앙상블 기법이라 할 수 있습니다.
전 세계의 머신러닝 개발자들의 기량을 겨루는 오픈 플랫폼 캐글(Kaggle)에서 XGBoost, LightGBM과 같은 앙상블 알고리즘이 머신러닝의 선도 알고리즘으로 인기를 모으고 있다는 점에서 앙상블 학습의 강력함을 확인할 수 있습니다.
2. 앙상블 학습 유형
앙상블 학습은 일반적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 세 가지의 유형으로 나눌 수 있습니다.
- 보팅(Voting)
- 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
- 서로 다른 알고리즘을 여러 개 결합하여 사용
- 보팅 방식
- 하드 보팅(Hard Voting)
- 다수의 분류기가 예측한 결과값을 최종 결과로 선정
- 소프트 보팅(Soft Voting)
- 모든 분류기가 예측한 레이블 값의 결정 확률 평균을 구한 뒤 가장 확률이 높은 레이블 값을 최종 결과로 선정
- 하드 보팅(Hard Voting)
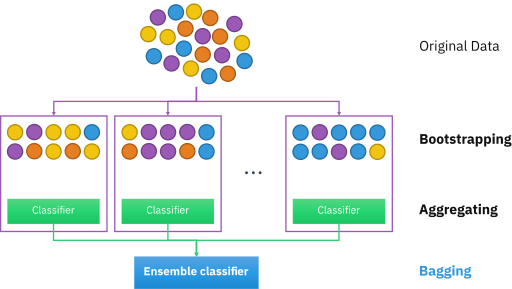
- 배깅(Bootstrap AGGregatING, Bagging)
- 데이터 샘플링(Bootstrap) 을 통해 모델을 학습시키고 결과를 집계(Aggregating) 하는 방법
- 모두 같은 유형의 알고리즘 기반의 분류기를 사용
- 데이터 분할 시 중복을 허용
- Categorical Data : 다수결 투표 방식으로 결과 집계
- Continuous Data : 평균값 집계
- 과적합(Overfitting) 방지에 효과적
- 대표적인 배깅 방식 : 랜덤 포레스트 알고리즘
- 부스팅(Boosting)
- 여러개의 분류기가 순차적으로 학습을 수행
- 이전 분류기가 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에게 가중치(weight)를 부여하면서 학습과 예측을 진행
- 계속하여 분류기에게 가중치를 부스팅하며 학습을 진행하기에 부스팅 방식이라고 불림
- 예측 성능이 뛰어나 앙상블 학습을 주도
- 대표적인 부스팅 모듈 – XGBoost와 AdaBoost, GradientBoost
- 보통 부스팅 방식은 배깅에 비해 성능이 좋지만, 속도가 느리고 과적합이 발생할 가능성(오답에 대해 높은 가중치를 부여하므로 정확도가 높게 나타나지만, 그렇기 때문에 outlier에 취약할 수 있음)이 존재하므로 상황에 따라 적절하게 사용해야 함.

- 스태킹(Stacking)
- 개별 모델이 예측한 데이터를 다시 meta data set으로 사용해서 학습
- Stacking을 위해서는 2가지 개념의 모델이 필요 : 개별 모델들(그림에서의 Base Learner)과 최종 모델(그림에서의 Meta Learner)
- 기본적인 Stacking 방법의 경우 Base Learner들이 동일한 데이터 원본 데이터를 가지고 그대로 학습을 진행했기 때문에 overfitting 문제가 발생 -> 이를 방지하기 위해 배깅/부스팅에서의 부트스트래핑과 유사한 방식을 도입 => 크로스 벨리데이션(Cross Validation)으로 데이터를 쪼개는 것
- CV(Cross Validation) : data set을 k번 쪼개서 반복적으로 쪼갠 data를 train과 test에 이용하여(k-fold cross validation) 교차 검증을 하는 것(보통 10-fold cross validation이 안정적이라고 한다.)

<CV 기반의 Stacking 과정>

1. Base Learner들은 원본 데이터를 각 fold별로 쪼개어 train set을 이용하여 학습 진행
(ex. 4-fold CV의 경우 한 fold 마다 2개의 train set / 1개의 validation set / 1개의 test set이 생성)
2. Base Learner들은 각 fold 마다 학습한 모델을 validation set에서 계산한 결과를 집계, test set을 이용한 예측값은 평균을 내어 meta 모델에 사용하는 하나의 test set으로 만듦
(ex. 3개의 Base Learner를 사용 : Base Learner들은 각각 3개의 validation set / 1개의 test set 가짐)
3. 결과적으로, 모든 Base Learner의 validation set와 test set을, meta train set와 meta test 셋으로 활용하여 학습한 뒤, 최종 모델 생성
(ex. 4-fold CV의 경우 총 9개의 validation set를 meta train set로, 3개의 test set를 meta test set로 사용)
- CV 기반으로 Stacking을 적용함으로써 overfitting은 피하며 meta 모델은 '특정 형태의 샘플에서 어떤 종류의 단일 모델이 어떤 결과를 가지는지' 학습할 수 있게 됨(더욱 완성도 있는 모델을 완성)
- Stacking의 단일 모델은 어떠한 모델을 사용해도 상관없으며, 흡사 neural network처럼 2단이상의 deep한 stacking도 가능
- 스태킹 예시 코드는 여기를 참고
참고 자료
https://data-analysis-science.tistory.com/61
1. 앙상블(Ensemble) 기법과 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)
안녕하세요, 허브솔트에요. 저희 데이터맛집의 허브솔트 첫 글 주제로 앙상블이 당첨됐네요...! 요새 캐글의 상위권 메달을 휩쓸고 있는 대세 알고리즘이 앙상블 기법을 사용한 알고리즘의 한
data-analysis-science.tistory.com
http://www.dinnopartners.com/__trashed-4/
머신러닝 앙상블(Ensemble) 학습 – DINNO PARTNERS
1. 앙상블 학습이란? 앙상블 학습(Ensemble Learning)은 여러 개의 분류기를 생성하고, 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법을 말합니다. 강력한 하나의 모델을 사용하는대신 보
www.dinnopartners.com
https://kimdingko-world.tistory.com/186
[머신러닝 완벽가이드] 스태킹 앙상블
스태킹 앙상블¶ 스태킹(Stacking)은 개별 알고리즘의 예측한 데이터를 기반으로 다시 예측을 수행하는 방법입니다. 정리하면 개별 알고리즘이 예측한 결과를 최종 메타 데이터 세트로 만들어 별
kimdingko-world.tistory.com
'AI > AI 지식' 카테고리의 다른 글
| [Python] *args, **kwargs 는 무엇이며, 왜 사용하는가? (0) | 2022.09.02 |
|---|---|
| [Statistics/Math] “likelihood”와 “probability”의 차이는 무엇일까요? (0) | 2022.08.23 |
| [Python] 파이썬에서 namespace란 무엇인가요? (0) | 2022.08.23 |
| [Deep Learning] 오버피팅일 경우 어떻게 대처해야 할까요? (0) | 2022.08.23 |
| [Machine Learning] Markov Chain을 고등학생에게 설명하려면 어떤 방식이 제일 좋을까요? (0) | 2022.08.23 |