
728x90
1. Seq2Seq with attention Encoder-decoder architecture Attention mechanism
sequence to sequence의 대표적 예시는 기계 번역이 있다.
Seq2Seq Model
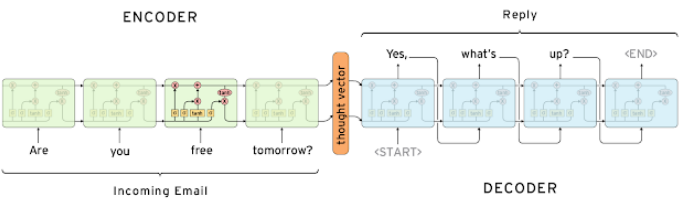
- 인코더와 디코더로 구성되어 있다.
- 챗봇을 예시로 들자면, 인코더에 특정 문장이 입력으로 주어졌을 때 디코더에서 이에 알맞는 대답을 예측하여 생성 모델이다.
- 입력을 처리하는 RNN 모델을 인코더, 출력을 처리하는 RNN 모델을 디코더라 한다.
- 위의 두 RNN 모델은 파라미터를 공유하지 않는다.
- RNN 모듈로는 LSTM을 사용한다.
- 인코더의 마지막 타임 스텝의 hidden state 벡터를 디코더 RNN의 입력($h_{0}$)으로 사용한다.
- 디코더의 입력 벡터로 처음에는 Start of Sentence라는 의미의 <SoS>를 넣어주고, 출력으로 End of Sentence라는 의미의 <EoS>가 나오면 디코딩을 멈춘다.
Seq2Seq Model with Attention
- 고정 길이 벡터인 hidden state 벡터를 통해 정보들이 전달되고, 마지막 hidden state 벡터에 그 모든 정보를 욱여넣으면 bottleneck 문제가 발생할 수 있다. -> 이때 attention을 Seq2Seq 모델의 추가 모듈로 사용하면 문제를 해결할 수 있다.
- LSTM 구조로도 long-term dependency 문제를 완전히 해결할 수 있는 것은 아니다.(*입력문장을 거꾸로 읽는 과정을 추가하여 문제를 해결하는 방안도 존재)
- 매 타임 스텝마다 발생한 hidden state 벡터 모두를 활용하자는 것이 attention 모듈의 기본적인 아이디어

- 합이 1인 형태의, 상대적인 가중치로 이뤄진 벡터, 즉 softmax layer의 output를 어텐션 벡터라 부른다.
- decoder RNN의 hidden state 벡터와 Attention output을 concatenate한 것이 $\hat{y_{1}}$ 이다.
- 중간에 틀린 단어를 출력했더라도, 그 다음에 올 단어를 올바르게 넣어줄 수 있다.
4. 위에서는 디코더와 인코더의 hidden state 벡터를 내적으로 계산하여 attention score를 구했지만 다른 방법들도 있다.

Attention is Great!
- 기계번역 성능 크게 높임
- 보틀낵 문제를 해결
- 기울기 소실 문제 해결
- 해석 가능성 제공 - 디코더가 각 타임 스텝을 예측할 때 인코더 상의 어떤 단어에 집중했는지 알 수 있게 됨
2. Beam Search
Greedy decoding
- 그때그때 바로 다음 스텝의 단어를 예측하는 디코딩
- 단어를 한 번이라도 잘못 예측하면 다시 되돌릴 수가 없음
Exhaustive search 완전 탐색
- 모든 경우의 시퀀스를 탐색하는 방법이다. 따라서 시간 복잡도가 매우 크다.
Beam search
- greedy decoding와 exhaustive search의 중간
- k개씩의 단어를 생성하여 확률적으로 더 답과 가까운 단어를 탐색한다.
- k는 보통 5 ~ 10이다.
- score는 모두 음수이고 그 중 가장 높은 score를 보이는 단어를 채택한다.
- 로그함수는 단조증가함수이므로 x값이 오르면 y값도 오르는 식(그 반대도 마찬가지)이기 때문.
- 국소적 최적값을 내는 것이기 때문에 항상 global 최적값과 일치할 순 없다.
- 다만 완전 탐색보다 훨씬 효율적인 방법이다.
- 그리디 디코딩은 <END> token을 만나면 문장이 끝난 것이지만 빔 서치는 각기 다른 hypotheses가 각기 다른 타임 스텝에서 <END> token을 발생시킬 수 있다.
- 한 hypotheses가 <END> token을 생성했다면 그것은 그대로 디코딩을 끝내고 임시 공간에 저장한다.
- 그리고 이어서 나머지 hypotheses에 대한 빔 서치 디코딩을 실행한다.
Stopping criterion
- 사전에 정한 최대 디코딩 타임 스텝 T를 기준으로 중단
- 완료된 hypotheses의 개수가 n 개 이상일 때(임시 공간에 얼마나 저장되는지를 통해 판단) 중단
Finishing up
- 최종적으로 디코딩이 완료된 hypotheses 리스트를 갖게 된다. 이 중에서 가장 높은 score를 택한다. 이때 로그 버전의 joint probability값이 가장 큰 hypotheses를 최종 결과물로 삼는다.
- 긴 시퀀스에 대해서는 낮은 score가 매겨지는 부작용이 발생하므로, 길이로 나누어 score를 정규화한다.
3. BLEU score
1. precision : 예측된 결과가 우리에게 노출되었을 때 우리가 실질적으로 느끼는 정확도.
2. recall : 검색했을 때 실제로 관련된 문서가 얼마나 검색되었는지.
3. f-measure(f1score) - 조화 평균 사용
* 산술 ≥ 기하 ≥ 조화
BLEU score
- 개별 단어 레벨에서 얼마나 공통된 단어가 많이 나왔는지
- 연속된 n개의 단어가 얼마나 나왔는가
- 번역에서, precision만을 고려, recall은 x
- 1~4 gram의 precision 고려
- 원래의 문장과 비교하여 얼마나 빠짐없이 번역을 했는가가 중요하다기보다는
- 이미 도출된 결과만을 보고 느끼는 정확도

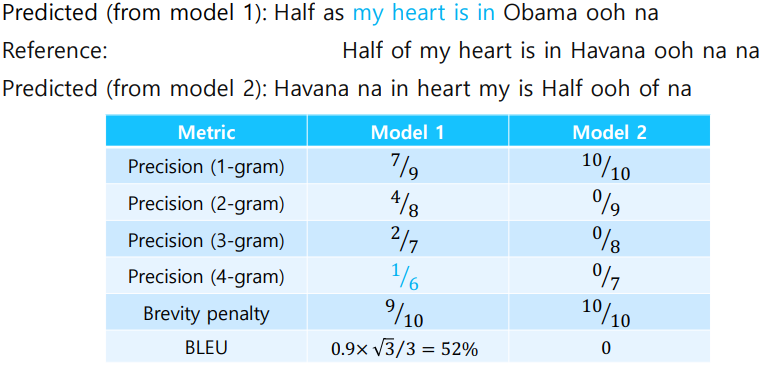
- 4개의 precision을 모두 곱한 후 4제곱근 ( =기하 평균)
- 조화 평균 사용하지 않은 이유 : 작은 쪽의 값에 너무 큰 가중치를 부여하므로
- brevity penalty
- min(1, pred/ref) 부분
- prediction이 짧아진다면 그에 맞춰서 precision도 낮춰주겠다는 의미
- recall의 최댓값을 의미하기도 함
- 예시 문제
728x90
'AI > AITech 3기' 카테고리의 다른 글
| [Docker] Docker compose 커맨드 사용법 (0) | 2022.06.29 |
|---|---|
| [Week8] 2. 자연어 처리 Part 2 (0) | 2022.03.20 |
| [Week8] 1. 자연어처리 Part 1 (0) | 2022.03.18 |
| [이미지 분류] 7강 Training & Inference 1 (2) | 2022.02.22 |
| [이미지 분류] 3강 Dataset (0) | 2022.02.21 |