
1. Basics of Recurrent Neural Networks (RNNs)

기본 구조는 위와 같다.
t번째 hiddent state vector를 구하는 방법은 다음과 같다.

구체적인 계산 과정은 다음과 같다.
1) $X_{t}$가 3차원 벡터, $h_{t-1}$가 2차원 벡터라 가정하면, 이 두 벡터를 연결한 5차원 벡터가 $h_{t}$가 되도록 하는 W(linear transformation matrix)이 필요하고 $h_{t}$는 hidden state 벡터이므로 2차원이다.
2) 우선 형태는 2(hidden state 벡터의 차원) by 5(hidden state 벡터의 차원 + x 입력 벡터의 차원)라는 것을 알 수 있다.

3) 이 계산을 다시 분해하면 아래와 같은 식이 도출된다.

$$W_{xh}x_{t} + W_{hh}h_{t-1}$$
따라서 직관적으로, $W_{xh}$는 $W_{xt}$를 $h_{t}$로 변환해주고, $W_{hh}$는 $W_{ht-1}$를 $h_{t}$로 변환해준다고 할 수 있다.

그리고 또 한번 W(linear transformation matrix)를 곱해주면 $y_{t}$가 도출된다.

$W_{hy}$또한 $W_{h}$처럼 $w_{ht}$를 $y_{t}$로 변환해주는 역할을 하는 것으로 이해할 수 있다.
이렇게 선형 변환을 해서 얻어진 아웃풋 벡터는 이진분류를 수행하게 되면 ①1차원인 어떤 scala 값이 되고, ②여기에 시그모이드 함수를 적용해서 ③이진분류의 확률 값을 예측 값으로 계산하게 된다.
다중분류를 수행하는 경우에는 ①$y_{t}$가 클래스 개수만큼의 차원을 가지는 벡터가 나와서 추가로 ②소프트맥스를 통과한 후, ③분류하고자 하는 클래스와 동일한 개수 만큼의 확률 분포를 얻을 수 있게 된다.
2. Types of RNNs
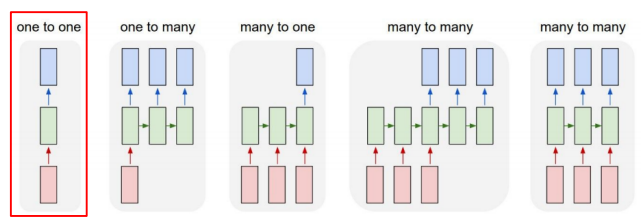
1. One-to-one : 표준의 신경망 구조 ex. feed forward
2. One-to-many : ex. 이미지 캡션 - 어떤 타임 스텝으로 이루어져 있지는 않은 단일한 입력(하나의 이미지) -> 이 이미지에 대한 설명글을 예측 혹은 생성하기 위해서 필요한 단어를 각 타임 스텝별로 순차적으로 생성하게 되는 형태의 아웃풋
3. Many-to-one :
- 입력 시퀀스를 이 입력으로 받은 후에 최종 값을 마지막 타임 스텝에서 비로소 출력으로 내어주는 형태가 일반적인 케이스가 된다.
- 센티멘트 크래스케이션 혹은 감정 분석이 이에 해당
- "i love movie"라는 입력 문장이 주어짐 -> 이 각각의 단어를 워드 임베딩 벡터 형태로 바꿈 -> 각 타임 스텝에서 이를 입력으로 받음 -> rnn 모듈이 입력으로 쭉 주어지는 데이터를 잘 처리 -> 마지막 타임 스텝에서 나온 그 $h_{t}$를 가지고 최종적인 output layer를 적용함 -> 긍정 혹은 부정에 해당하는 값을 예측
- 이 문장이 길이가 다른 "i hate this movie"라고 하는 경우 -> 길이가 달라진 만큼 rnn셀이 그에 맞추어서 쭉 확장이 되어서 반복적으로 수행 -> 문장을 모두 다 읽어들인 후 마지막 타임 스텝에서 나온 $h_{t}$를 가지고 output layer를 적용 -> 최종 예측값 얻음
4. Many-to-many(3번째 그림) : 입력과 출력이 모두 시퀀스 형태를 띄는 경우 - 기계 번역
- "i go home"이라는 문장이 주어짐 -> 이 문장을 끝까지 다 읽음 -> 마지막 타임 스텝에서 이 문장에 해당하는 한글 번역인 나는 집에 간다라는 한글 단어를 순차적으로 예측 값으로 내어줌
- 그래서 지금 이 구조(3번째 그림 참고)에서는 타임 스텝이 총 5개로 이루어져 있고 이 세 번째 타임 스텝까지는 주어진 문장을 끝까지 읽었다가 이 문장을 다 읽은 후부터 출력 단어 혹은 이 문장의 번역에 해당할 법한 예측 단어를 생성 해준다는 것을 알 수 있음
5. Many-to-many(4번째 그림) : 입력이 주어질 때마다 예측을 수행하는 형태의, 딜레이가 전혀 존재하지 않는 혹은 허용이 되지 않는 형태의 테스크 - 각 단어별로 문장 성분이나 품사를 예측하는 pos tagging, video classification on frame level
- 비디오가 어떤 시간순으로 이루어진 각각의 이미지 프레임이라고 생각을 할 때 그 이미지가 각 타임 스텝마다 주어지면 각 프레임별로 예측을 수행할 때 실시간성이 요구되는 경우에 매니 투 매니 구조를 생각할 수 있게 된다.
3. Character-level Language Model
- "hello"라는 시퀀스를 학습하는 예시이다.
- $h_{t} = tanh(W_{hh}h_{t-1} + W_{xh}x_{t} + b)$
- $Logit = W_{hy}h_{t} + b$
- 4개의 캐릭터 중 한 캐릭터로서 그다음에 나올 캐릭터를 예측하는 테스크를 수행해야함
- output 레이어의 노드 수는 사전의 크기와 동일한 4개의 차원으로 이루어진 output 벡터가 나옴
- 선형 변환을 하여서 얻어진 output 벡터를 다중 분류을 수행하기 위해 softmax 레이어에 통과
- 소프트맥스의 입력으로 들어가는 logit 값으로서의 이 output 벡터가 제일 큰 값을 가질 때 해당 확률 값이 가장 큰 값으로 나오게 됨
- 사전에 정의된 것이 hello였다면 이 경우는 예측값이 o라는 캐릭터에 가장 큰 확률을 부여한 값으로 나오게 될 것이지만 정작 groud truth 캐릭터는 다음에 나올 캐릭터가 e임
- 2번째 차원의 확률 값을 최대한 높이도록 학습을 진행해야함
- 여기서는 다중 분류 task를 다루기 때문에 softmax 레이어의 output에 ground truth 즉 e라는 캐릭터는 [0100]이라는 100%의 확률을 몰아준 것이 ground truth 벡터
- 따라서 [0100]와 여기에서 나온 소프트 맥스 벡터가 최대한 가까워지도록 하는 softmax loss를 적용해서 이 네트워크을 학습
- 이러한 학습 과정을 통해 $w_{hh}$, $w_{xh}$, output 벡터를 만들어주는 레이어의 파라미터인 $w_{hy}$가 전체적으로 역전파에 의해서 학습이 진행
- 이 task에서 주목할 것
- 세 번째 타임 스텝과 네 번째 타임 스텝이 동일하게 l라는 입력이 들어가는 이 상황에서도 세 번째 타임 스텝에서는 다음 캐릭터로서 l을 예측 값으로 할 수 있어야 하고 이 네 번째 타임 스텝에서는 또 같은 l이라는 입력이 들어왔을 때도 이번엔 o라는 다음 캐릭터를 이제 예측해야 된다
- rnn이 이러한 테스크를 수행하기 위해서는 지금 현재 타임 스텝에서 들어온 입력뿐만 아니라 이 세 번째에서는 그 전에 나왔던 캐릭터는 바로 h와 e까지만 나왔고 그리고 네 번째 타임 스탭에서는 그전까지의 정보는 이제 h, e와 그다음에 l까지가 나왔다는 등의 정보를 알 수 있어야 한다
- 이러한 정보는 전 타임 스텝에서 넘어오는 hidden state 벡터인 $h_{t-1}$에 해당하는 벡터가 해당 정보를 잘 표현함으로써 이러한 테스크를 적절하게 수행할 수 있다.
- inference(추론) 수행
- 첫 번째 캐릭터만을 입력으로 줌
- 해당 타임 스텝에서의 예측값으로서의 다음 타임 스텝의 캐릭터를 얻어낸 후 이 예측값을 그 다음 타임 스텝의 입력으로 재사용
- 다음 타임 스텝에 이를 입력으로 넣어주게 되면 그러면 또 그 다음 캐릭터 예측
- 2,3번 반복

Backpropagation through time (BPTT)
- 기존 버전 : 한 시퀀스를 한 번에 gpu를 통해서 학습, 여기에서 나온 output을 모두 계산한 후 loss 적용하고, 역전파까지 수행
Q. 시퀀스의 길이가 매우 길어진다면 ?
현실적으로 시퀀스의 길이가 굉장히 길어지면 한꺼번에 처리할 수 있는 정보나 데이터의 양이 한정된 gpu 리소스 내에서의 메모리에 모두 다 담기지 못할 수 있음 => 보통 truncation(잘게 자르는)이라는 즉 연속된 시퀀스를 군데군데 잘라서 해당하는 어떤 제한된 길이의 시퀀스만으로 학습을 진행하는 방식을 채택

- BPTT(backpropagation through time) : truncated RNN
- 나눠진 chunk 안에서 역전파와 순전파 진행
- 그 과정에서 RNN의 파라미터를 학습 -> 어떻게? hidden state 벡터를 통해 가능
- 역전파와 순전파는 나눠진 chunk안에서 진행되지만 hidden state 벡터는 고정으로 매 타임 스텝마다 업데이트 수행

- hidden state 벡터 시각화 예시

RNN의 한계점
Vanishing/Exploding Gradient Problem
역전파 과정에서 같은 행렬을 매 타임 스텝마다 곱해주는 과정에서 발생하는 문제

4. Long Short-Term Memory (LSTM) Gated Recurrent Unit (GRU)
RNN의 장기 의존성 문제 (long-term dependency problem)
- 타임 스텝이 길어질수록 영향을 주지 못함
- 이러한 문제가 발생하는 이유는 입력 데이터가 RNN Cell을 거치면서 특정 연산을 통해 데이터가 변환되어, 일부 정보는 타임 스텝마다 사라지기 때문이다.
LSTM
- RNN 셀의 장기 의존성 문제를 해결 -> 어떠한 변환 없이 cell state 정보가 전달됨
- 장기 기억 $c_{t−1}$은 셀의 왼쪽에서 오른쪽으로 통과하게 되는데 forget gate를 지나면서 일부 기억(정보)을 잃고, 그 다음 덧셈(+) 연산으로 input gate로 부터 새로운 기억 일부를 추가한다. 이렇게 만들어진 $c_{t}$는 별도의 추가 연산 없이 바로 출력
- 학습 또한 빠르게 수렴
- 구조(아래 그림)
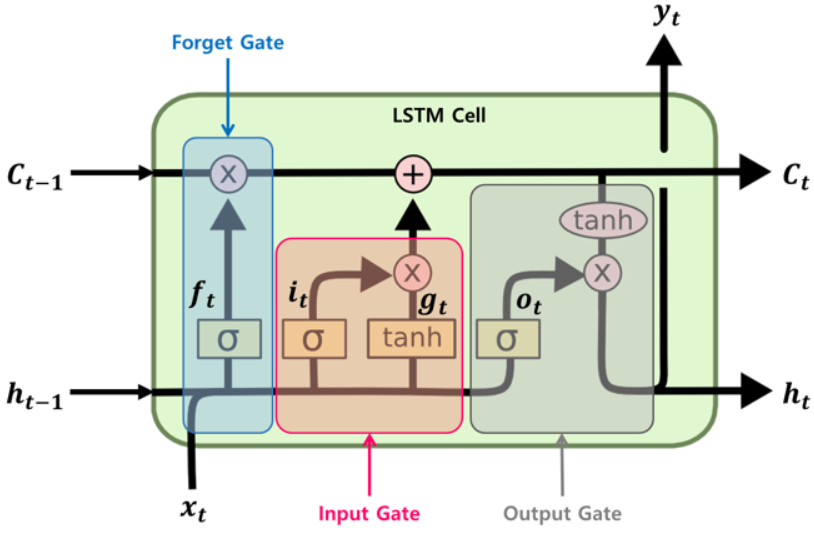

- $C_{t}$는 장기적으로 기억을 가지고 가는 반면, $h_{t}$는 $C_{t}$에서 추가적인 계산을 통해 얻은 당장에 필요한 정보, 바로 다음 스텝에 출력할 벡터가 된다.
- "i go home"이라는 문장이 주어지고 go 까지 입력했다고 가정하자. cell state 벡터는 따옴표가 열려있고 언젠가 따옴표로 문장을 닫아야한다는 정보를 담고 있다. 반면 hidden state 벡터는 go 다음에 올 단어가 home이라는 정보를 담게 된다.
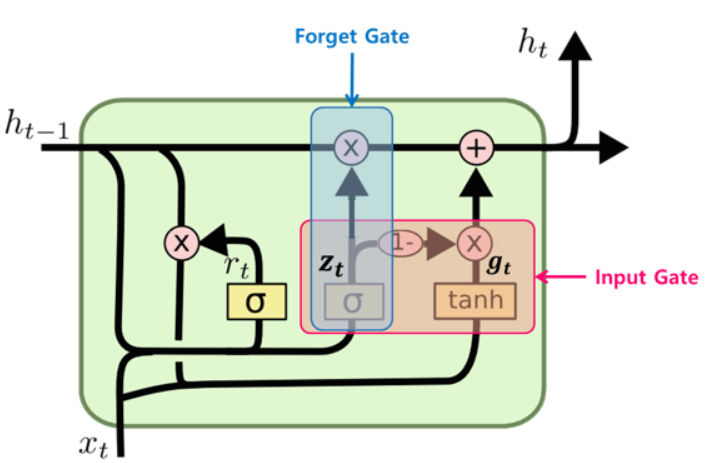
GRU
- LSTM을 보다 경량화한 모델이다.
- 적은 메모리 사용
- 더 빠른 계산 속도
- LSTM과 구별되는 가장 큰 특징
- hidden state 벡터와 cell state 벡터를 hidden state 벡터로 일원화했다.
- 다만 GRU에서 hidden state 벡터의 역할은 LSTM의 cell state 벡터의 역할과 유사하니 헷갈리지 말자.
- 독립된 두 게이트(input, forget)였던 것을 하나($z_{t}$)로 처리했다.
- hidden state 벡터와 cell state 벡터를 hidden state 벡터로 일원화했다.
* LSTM과 GRU에 대한 구체적인 설명은 여기에 잘 정리되어 있다.
참고
GitHub - ExcelsiorCJH/Hands-On-ML: Hands-On Machine Learning
Hands-On Machine Learning. Contribute to ExcelsiorCJH/Hands-On-ML development by creating an account on GitHub.
github.com
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 <!-- by colah --> Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
'AI > AITech 3기' 카테고리의 다른 글
| [Docker] Docker compose 커맨드 사용법 (0) | 2022.06.29 |
|---|---|
| [Week8] 3. 자연어 처리 Part 3-Sequence to Sequence with Attention (0) | 2022.03.20 |
| [Week8] 1. 자연어처리 Part 1 (0) | 2022.03.18 |
| [이미지 분류] 7강 Training & Inference 1 (2) | 2022.02.22 |
| [이미지 분류] 3강 Dataset (0) | 2022.02.21 |