
1. 모수
- 통계적 모델링의 목표 = 적절한 가정 위에서 확률분포 추정 = 기계학습 & 통계학의 공통 목표
- 그러나 한정된 데이터로 모집단의 정확한 분포를 알아내기란 불가능 -> 근사적으로 확률분포 추정
- 예측 모형의 목적 : 분포를 정확하게 맞추는 것 < 데이터와 추정 방법의 불확실성을 고려, 위험을 최소화하는 것
2. 모수 추정 방법
- 모수적 방법론 : 데이터가 특정 확률분포를 따른다고 선험적으로 가정, 그 분포를 결정하는 모수를 추정
- 비모수적 방법론 : 특정 확률분포 가정 X, 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수 방법론
- 비모수적 방법이라해서 모수가 없다는 것 아님. 모수의 개수가 불확실한 것을 말함.
- 기계학습의 많은 방법론은 비모수 방법론에 속함
3. 모수 추정
① 모양 관찰을 통해 확률 분포 가정 : 각 분포마다 검정하는 방법들이 있으므로 모수 추정 후 반드시 검정 필요
- 데이터가 이진일 경우 : 베르누이분포
- 데이터가 n개의 이산적인 값을 가지는 경우 : 카테고리분포
- 데이터가 [0,1] 사이에서 값을 가지는 경우 : 베타분포
- 데이터가 0 이상의 값을 가지는 경우 : 감마분포, 로그정규분포 등
- 데이터가 R 전체에서 값을 가지는 경우 : 정규분포, 라플라스분포 등
② 데이터로 모수 추정
- 정규분포의 모수 - 평균, 분산
- 표본평균 : 기대값
- 표본분산 : N 이 아닌 N - 1로 나누는 이유는 불편 추정량 구하기 위함
- 불편(unbiased) 추정량 : 추정량의 기대값과 실제 모수와의 편차를 bias 라 함. 불편 추정량은 그 편차가 없는 추정량을 뜻함. 아래의 등호를 만족하면 추정량의 기대값 = 실제 모수로, unbiased한 추정량이 된다.
- $\mathbb{E}[\bar{X}] = \mu, \mathbb{E}[S^{2}] = \sigma^{2}$

* 참고 : 통계량(statistic)의 정의
-> 통계학에서는 표본의 분포가 무엇이든지 상관없이 정해진 함수가 있을 때에, 표본의 함수값을 통계량으로 정의한다.
-> 위에서는 표본평균, 표본분산을 통계량으로 제시
- 표집분포
- 통계량(표본평균, 표본분산)의 확률분포를 표집분포라 함
- 표본평균의 표집분포 - N이 커질수록(= 데이터가 커질수록) 정규분포 따름 -> 중심극한정리, 이때 모집단의 분포가 정규분포 따르지 않아도 성립함
4. 확률밀도함수와 가능도함수
- 모수 $\theta$ : 이미 알고 있는 상수계수, $x$ : 변수
- 모수 추정 문제라면 ? 이미 실현된 특정 표본값 $x$는 알고 있지만, 모수 $\theta$는 모름
1) 이때는 $x$를 이미 알고 있는 상수계수로, $\theta$를 변수로 상정
2) 함수의 값 자체는 변함없이 주어진 $x$가 나올 수 있는 확률밀도임
=> 확률밀도함수에서 모수를 변수로 보는 경우 -> 가능도함수라 함
따라서 같은 함수라도 확률밀도함수로 보면 $p(x;\theta)$ 라 표기, 가능도함수로 보면 $L(\theta;x)$ 라 표기
$$L(\theta;x) = p(x;\theta)$$
5. 확률밀도함수와 가능도함수 - 수식
* 오독을 방지하고자 상수인 경우 첨자를 붙여 표기함
1) 정규분포의 확률밀도함수 : 단변수 함수(입력 변수가 $x$ 1개)
$$p(x;\mu_{0},{\sigma_{0}}^{2}) = \frac{1}{\sqrt{2\pi{\sigma_{0}^{2}}}}\exp\left(-\frac{(x-\mu_{0})^{2}}{2{\sigma_{0}}^{2}}\right)$$
2) 가능도 함수 : 다변수 함수(입력 변수 2개)
$$L(\mu,\sigma^{2};x_{0}) = \frac{1}{\sqrt{2\pi{\sigma^{2}}}}\exp\left(-\frac{(x_{0}-\mu)^{2}}{2\sigma^{2}}\right)$$
6. 최대가능도 추정법
- 표본평균, 표본분산(추정된 모수)은 확률분포마다 달라짐
- 이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나 : 최대가능도 추정법(maximum likelihood estimation, MLE)
- 가능도 함수는 모수 $\theta$를 따르는 분포가 임의의 데이터 x를 관찰할 가능성이 크냐 적냐이지, 확률이 아니다.
- 최대가능도 추정법으로 찾은 모수는 $\hat\theta_{MLE}$ 라 표기한다.
- 아래 식을 참고해 설명하면, 표본값 $x$가 나올 가능도(확률밀도)가 가장 높은 확률분포를 선택한다는 의미(선택된 확률분포의 모수를, 구하고자 하는 모수로 추정)
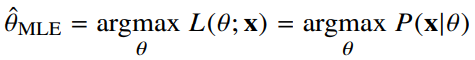
- 데이터 집합 X가 독립추출될 경우 로그가능도 최적화함 : 연산이 곱셈 -> 덧셈으로 바뀜
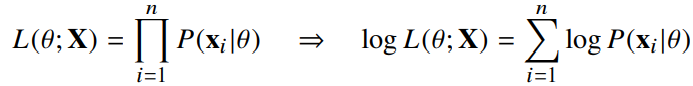
7. 로그 가능도 사용 이유
1. 연산이 곱셈 -> 덧셈으로 바뀌면서 큰 숫자도 계산 가능
2. 데이터가 독립일 경우, 로그 이용 시 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀 수 있으므로 컴퓨터가 연산 가능
3. 경사하강법으로 가능도를 최적화할 때 -> 미분 연산 시 로그 가능도 사용 시 연산량 대폭 감소 ($O(n^2) -> O(n)$)
4. 대개의 손실함수는 경사하강법 사용 -> 음의 로그 가능도 최적화하게 됨
5. 로그 변환에 의해서는 최대값 위치가 불변
6. 반복시행으로 인한 복수 표본 데이터의 경우 : 결합 확률밀도함수가 동일한 함수의 곱으로 나타나는 경우가 많은데 이때 로그 변환에 의해 곱셈이 덧셈이 되어 계산이 단순해짐
8. 최대가능도 추정 : 정규분포
- 정규분포를 따르는 확률변수 X로부터 독립적인 표본 n개를 얻었을 때 최대가능도 추정법을 사용해 모수 추정하면?


위의 식을 $\mu, \sigma$ 각각에 대해 미분했을 때 모두 0이 되는 경우 모수로 추정($\sigma^{2}$로 미분해도 무방)


9. 최대가능도 추정 : 카테고리 분포
* 카테고리 분포의 모수는 총합이 1이라는 제약 만족해야함(∵확률질량함수)
이 식에서 데이터 $x$는 모두 k개의 원소를 가지는 원핫인코딩(one-hot-encoding)벡터다. 그런데 N 번의 반복 시행으로 표본 데이터가 $x_{1},⋯,x-{N}$이 있는 경우에는 모두 독립이므로 전체 확률밀도함수는 각각의 확률질량함수의 곱과 같다.


계산의 편리를 위해 $k$번째 원소가 나온 횟수를 $N_{k}$라 표기하고, $N_{k} = \sum_{i=1}^{N}x_{i,k}$ 라 치환하자.
그럼 위의 결과는 $\log L = \sum_{k=1}^{K}(log\mu_{k}\cdot N_{k})$ 가 된다.
이때 모수는 총합이 1이라는 제약조건을 만족해야하며, 이는 라그랑주 승수법을 사용해 로그가능도에 제한조건을 추가한 새로운 목적식을 만들 수 있다.

위 목적식을 모수로 각각 미분하여 모두 0이 나오게 하는 값을 구하면 된다.

최종적으로 추정된 모수는 아래와 같다.

최대가능도 추정법에 의한 카테고리 분포의 모수 : 각 범주값이 나온 횟수($N_{k}$)와 전체 시행횟수(N)의 비율이다.
10. 딥러닝에서의 최대가능도 추정법
1. 딥러닝 모델의 가중치를 $\theta$ 라 하면 분류 문제에서 softmax 벡터는 카테고리분포의 모수를 모델링
2. 원핫벡터로 된 정답 레이블을 관찰 데이터로 활용해, 확률분포인 softmax 벡터의 로그가능도 최적화 가능
3. 수식
$$\hat{\theta }_{MLE} = \underset{\theta}{argmax}\frac{1}{n}\sum_{i=1}^{n}\sum_{k=1}^{K}y_{i,k}\log(MLP_{\theta}(X_{i})_{k})$$
11. 쿨백-라이블러 발산
- 기계학습에서 사용되는 손실함수 유도 : 모델이 학습한 확률분포와, 데이터에서 관찰된 확률분포의 거리를 통해 유도됨 => 데이터공간 상의 2 개의 확률분포 $P(x), Q(x)$ 에 대해 두 확률분포 사이의 거리 계산하는 데 쓰이는 함수는 아래와 같다.
1) 총변동 거리
2) 쿨백-라이블러 발산
3) 바슈타인 거리
- 분류 문제에서 정답레이블을 P, 모델 예측을 Q라 두면 최대가능도 추정법은 쿨백-라이블러 발산을 최소화하는 것과 동일
* 참고 자료
9.2 최대가능도 추정법 — 데이터 사이언스 스쿨
모멘트 방법으로 추정한 모수는 그 숫자가 가장 가능성 높은 값이라는 이론적 보장이 없다. 이 절에서는 이론적으로 가장 가능성이 높은 모수를 찾는 방법인 최대가능도 추정법에 대해 알아본
datascienceschool.net
* 추가 학습할 것
1. 라그랑주 승수법
2. 쿨백-라이블러 발산
'AI > AITech 3기' 카테고리의 다른 글
| [AI Math] 9강 CNN 첫걸음 (0) | 2022.01.23 |
|---|---|
| [AI Math] 8강 베이즈 통계학 맛보기 (0) | 2022.01.23 |
| [AI Math] 6강 확률론 맛보기 (0) | 2022.01.22 |
| [AI Math] 5강 딥러닝 학습 방법 이해하기 (0) | 2022.01.22 |
| [AI Math] 4강 경사하강법 매운맛 (0) | 2022.01.22 |