
최적화 방법은 우리가 기본적으로 배운 SGD 말고도 다양한 방법이 존재한다.
1. Generalization
- 모델이 처음 보는 데이터에 대해 얼마나 잘 판단하는지의 척도
- Generalization gap의 크기와 Generalization performance는 반비례 관게로, 학습 에러와 테스트 에러가 비슷해서 그 gap이 작으면 일반화 성능이 좋다고 말한다.
- 다만 학습 데이터의 성능 자체가 나쁘면 Generalization performance가 좋아도 좋은 게 아니다. 테스트 에러와 학습에러가 비슷한 수치이지만, 그 수치가 상당히 클 경우를 말한다.
2. Fitting
일반화가 잘 된 경우 : Balanced
학습 모델에 지나치게 최적화되어 일반화가 안된 경우 : Over-fitting
모델을 적게 학습시켜 학습 자체가 부족한 경우 : Under-fitting
3. Cross-Validation 교차검증
- 하이퍼파라미터 튜닝을 위한 장치로,
- 8:2로 train data, test data를 나눈 후
- train data를 데이터만 훈련하는 train data와 하이퍼파라미터 튜닝을 위한 valid data로 나눈다. 보통 5등분하여 4-fold동안 학습을 하고, 5-fold의 데이터를 가지고 하이퍼파라미터 튜닝을 위한 검증을 한다.
- 그리고나서야 test data를 통해 학습된 데이터와, 튜닝된 하이퍼파라미터에 대한 올바른 평가가 이루어진다.
- 만약 test data로 하이퍼파라미터 튜닝을 한다면 그 자체로 cheating!
4. Bias and Variance Tradoff
손실함수를 최소화하기 위해선 분산과 편향, 노이즈를 통해 하여야한다. 여기서 분산과 편향은 반비례 관계이므로 잘 조절하는 것이 관건이다.
- 언더피팅 : 예측값들과 정답이 대체로 멀리 떨어져 있으면 결과의 편향(bias)이 높다고 말하고 이를 언더피팅되었다고 말함
- 오버피팅 : 예측값들이 자기들끼리 대체로 멀리 흩어져있으면 결과의 분산(variance)이 높다고 말하고 이를 오버피팅되었다고 말함

5. Boostrapping
부트스트랩은 신발끈이라는 뜻의 단어로, N번의 subsampling으로 여러 모델을 만들고, 각각의모델로 평가, 평가를 평균내거나 투표한다.
6. Bagging(Bootstrapping aggregating, 앙상블과 같음)
- 여러 모델들이 부트스트래핑을 통해 훈련됨. 그리고 결과에 대해 평균을 내서 최종적인 답을 도출
- Parallel
7. Boosting
- 예측 -> 잘못 예측한 데이터에 한해 모델 생성 및 재예측 N번 -> 모델들 연결해 1개 모델로 만듦
- weak learners들을 시퀀셜하게 합쳐서 강한 모델을 만듦. 각 learner들은 이전 weak learner들의 실수로부터 학습한다.
- 연속적으로 작동
- Sequential
8. GD
- SGD : 1개 샘플로부터 그라디언트 계산
- 미니배치 GD : 가장 자주 사용됨. 보통128, 245개씩 적용함.
- 배치 GD : 한번에 전체 데이터 사용
9. 배치 사이즈 문제
- 큰 배치 활용 시 sharp minimizer로 수렴할 위험이 있으므로, 적은 배치 활용 시 flat minimizer로 수렴.
- generalization performance는 적은 배치 사이즈를 사용하는 것이 좋다.
- sharp minimizer, flat minimizer 란? 아래의 flat miniimum과 sharp minimum을 말한다.

10. Gradient Descent Methods
- SGD
- Momentum
- Nesterov accelerated gradient
- Adagrad(Adaptive gradient)
- RMSprop
- Adam(현재 가장 많이 쓰임)
GD

Momentum
- 직역하면 관성
- Idea : 이전 배치에서 그레디언트가 x방향으로 흘렀다면 그 정보를 활용해보자 -> 현재 주어져 있는 파라미터에서 그레디언트 계산, 그 그레디언트를 가지고 모멘텀 누적

$g_{t}$라는 그레디언트가 현재 들어왔다면 $a_{t+1}$가 계속 $g_{t}$를 버리지 않고 갖고 있는 것
$W_{t+1}$는 현재 그레디언트를 합친 누적값을 업데이트
Nesterov Accelearted Gradient(NAG)

누적을 하는 a가 gradient descent를 하는데, lookahead gradient를 계산하게 됨
-> t라는 곳에서 먼저 한 번 그레디언트를 계산을 하고 다시 그 위치의 값을 더한 값을 $a_{t+1}$로 삼음
-> $a_{t+1}$를 그레디언트값으로 삼아 기존 가중치에서 빼주어 가중치를 업데이트

모멘텀보다 빠르게 local minimum으로 수렴한다.
Adagrad
- 학습률를 정하는 효과적 기술 중 학습률 감소가 있다. 가장 간단한 구현 방법은 매개변수 전체의 학습률을 일괄적으로 낮추는 것이고 Adagrad는 이를 더욱 발전시켜, 각 매개변수에 알맞게 개별적으로 학습률값을 조정해준다.
- 개별 매개변수에 적응적(adaptive)으로 학습률을 조정하므로 Adagrad라는 이름이 붙는다.
- Adagrad는 과거의 기울기를 제곱하여 계속 더해간다. 이때 학습을 진행할수록 갱신 기울기가 약해지다 어느 순간 갱신량이 0이 된다. 이러한 문제를 해결하기 위해 RMSProp이라는 방법이 나오게 되었다 이는 과거의 모든 기울기를 균일하게 더하지 않고 먼 과거의 기울기는 서서히 잊으면서 새로운 기울기 정보를 크게 반영한다. 이를 지수이동이라 한다.
- 큰 움직임에 비례해 갱신 정도도 크게 작아지고, 지그재그로 움직이는 정도도 작아진다. 작은 움직임(작은 기울기)를 보인다면 그 반대로 작용한다.

classAdagrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] += grads[key] * grads[key]
prarms[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)위 코드에서 1e-7이라는 작은 값을 더해주는 이유는 self.h[key]에 0이 담겨 있다 해도 0으로 나누는 사태를 막아준다. 위의 수식에서 ϵ(epsilon)과 같은 역할이다.
Adadelta

학습율이 존재하지 않아, 하이퍼파라미터 튜닝할 것이 딱히 없어서(통제할 수 있는 것들이 적어서) 많이 쓰이지 않는다고 한다.
RMSProp
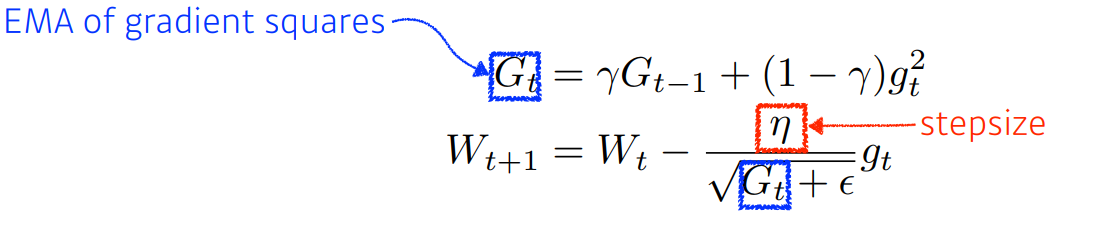
adadelta에서 stepsize를 추가한 것이다.
Adam
- Adagrad + Adam
- 하이퍼파라미터의 편향 보정이 진행
- $\beta_{1}$은 1차 모멘텀용 계수로, 보통 0.9로 설정하고
- $\beta_{2}$은 2차 모멘텀용 계수로, 0.999로 설정하는 것이 대개 좋은 결과를 얻는다.
- 모멘텀을 적용한 후, 여기에 추가적으로 adagrad의 특징(적응적으로 학습률을 조절하는 계산과정)을 적용한 방법

11. Regularization
Early stopping
말그대로 기존에 설정한 epoch보다 일찍 학습을 중단하는 것으로, 검증 데이터에 대한 loss가 설정한 수치 이상으로 커지면 학습을 중단한다.
Parameter Norm Penalty(Weight decay)
- 파라미터가 너무 커지지 않게 하는 것
- 큰 가중치에 대해서는 그에 상응하는 큰 페널티를 부과하여 오버피팅 억제(오버피팅은 가중치 매개변수의 값이 커서 발생하는 경우가 많기 때문)
- 부드러운 함수를 만들기 위함
- 부드러운 함수일수록 일반화 성능이 좋기 때문
- 아래의 알파기호는 정규화의 세기를 조절하는 하이퍼파라미터로, 알파값을 크게 설정할수록 큰 가중치에 대한 페널티가 커짐
- 아래 분모로 주어진 2는 파라미터 노름 페널티로 설정된 항의 미분값을 조정하는 역할의 상수

Data Augmentation
예를 들어 이미지 데이터라면, 이미지를 반전시키거나, 기울이거나, 이미지 식별이나 분류등에 영향을 끼치지 않는 선에서 변형하여 기존 데이터를 활용해 데이터를 증식시키는 것을 말한다.
Noise Robustness
Robustness는 견고성이라는 뜻이므로 노이즈에도 잘 작동하게 한다는 의미를 담은 방법이 되겠다.
이는 입력값이나 가중치에 노이즈를 랜덤으로 준다. 보다 일반화 성능을 높이기 위한 것이다.
mnist 데이터를 예로 들면, 깔끔하고 정확하게 쓰인 7뿐만 아니라, 흘겨쓴 7도 7로 인식될 수 있도록 일부러 노이즈를 준 데이터도 학습시킨다.
Label Smoothing : Mixup, CutMix

- 데이터도, 라벨도 섞어준다.
- 이렇게 하는 이유는 데이터의 라벨을 결정하는 어떤 경계선을 찾기 위함에 있다.
- 이 방법은 들인 노력이 적은 것에 비해 성능이 좋다고 한다.
Dropout
- 뉴런을 임의로 삭제하면서 학습
- 훈련 시 은닉층의 뉴런을 무작위로 골라 삭제
- 시험 때는 각 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱하여 출력
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
Batch Normalization
이전엔 가중치의 초깃값을 적절히 설정해 각 층의 활성화값 분포가 적당히 퍼지면서 학습이 잘 수행되었다면,
치 정규화는 활성화를 적당히 퍼뜨리도록 강제해보자는 아이디어에서 나온 방법이다.
- 장점
- 학습 속도 개선
- 초깃값에 크게 의존하지 않음(이전에는 초기값을 잘 설정하는 것이 중요했음)
- 오버피팅이 억제되어 드롭아웃 등의 필요성이 감소
- 방법
- 각 층에서의 활성화값이 정당히 분포되도록 조정하는 것이 목적이므로, 데이터 분포를 정규화하는 배치 정규화 계층을 신경망에 삽입
- 배치 정규화는 이름대로 미니배치를 단위로 정규화, 구체적으로는 평균이 0, 분산이 1이 되도록 정규화
- 배치 정규화 계층마다 이 정규화된 데이터에 고유한 스케일(곱셈)과 이동(덧셈) 변환을 수행: $y_{i} = \gamma \hat{x}_{i} + \beta$

참고자료
* 네이버 부스트캠프 강의자료
* 밑바닥부터 시작하는 딥러닝1
'AI > AITech 3기' 카테고리의 다른 글
| [DL Basic] 5강 Modern CNN - 1x1 convolution의 중요성 (0) | 2022.02.18 |
|---|---|
| [DL Basic] 4강 Convolution은 무엇인가 (0) | 2022.02.17 |
| [DL Basic] 2강 MLP (Multi-Layer Perceptron) (2) | 2022.02.10 |
| [DL Basic] 1강 Historical Review (2) | 2022.02.10 |
| [논문 리뷰] Efficient Estimation Of Word Representations In Vector Space(Word2Vec) (2) | 2022.02.08 |